引言
在数字时代,GitHub已经成为开发者社区的中心,托管了无数个开源项目和代码库。但是,众多的仓库中哪些项目真正引领了潮流?github上编程语言分布如何?仓库分类有哪些等问题。数据分析可以帮助找到答案,在本文中,将探讨GitHub上最受欢迎的项目,分析其具有的其他特征等问题。通过这个数据驱动的研究,将揭示GitHub生态系统中的一些有趣发现,深入了解开源开发的现状。
数据集来自开放数据集,于kaggle社区上获取,文附录将附上数据集与链接
数据集拥有215,029条数据,本文有对排名靠前的提取出来,感兴趣的也可以直接访问哈哈哈,个人也可以通过自己感兴趣的领域,对数据进行检索提取,去找到优质的github资源
字段备注
import pandas as pd
github_repo = pd.read_csv('E:/data/repositories.csv', encoding='utf-8')
github_repo“Most Popular Github Repositories (Projects)” 的数据集。以下是每个字段的解释:
- Name:GitHub 仓库的名称
- Description:GitHub 仓库的简要描述
- URL:GitHub 仓库的网址,是该仓库的唯一标识符
- Created At:GitHub 仓库的创建日期和时间,使用 ISO 8601 格式表示
- Updated At: 仓库的最近更新或修改日期和时间,使用 ISO 8601 格式表示
- Homepage: 与仓库相关的主页或导航页的网址,提供额外的信息或资源
- Size: 仓库的大小,以字节为单位,表示仓库文件和数据所占用的总存储空间
- Stars: 仓库收到的星标或点赞数量,表示其受欢迎程度或受到其他 GitHub 用户的关注程度
- Forks: 仓库被其他 GitHub 用户 fork 的次数
- Issues: 所有未关闭的 issue 的总数。
- Watchers: 监视或关注仓库以获取更新和更改的 GitHub 用户数量。
- Language: 主要编程语言。
- License: 使用许可证标识符提供的有关软件许可证的信息。
- Topics: 与仓库相关的主题或标签列表,帮助用户发现相关项目和感兴趣的主题。
- Has Issues:一个布尔值,指示仓库是否启用了问题追踪器。在这种情况下,为 true,表示它有一个问题追踪器
- Has Projects:一个布尔值,指示仓库是否使用 GitHub 项目来管理和组织任务和工作项。
- Has Downloads:一个布尔值,指示仓库是否向用户提供可下载的文件或资源。
- Has Wiki:一个布尔值,指示仓库是否有关联的 Wiki,提供额外的文档和信息。
- Has Pages:一个布尔值,指示仓库是否启用了 GitHub Pages,允许创建与仓库相关的网站。
- Has Discussions:一个布尔值,指示仓库是否启用了 GitHub Discussions,允许社区进行讨论和合作。
- Is Fork:一个布尔值,指示仓库是否是另一个仓库的 fork。在这种情况下,为 false,表示它不是一个 fork。
- Is Archived:一个布尔值,指示仓库是否已归档。归档的仓库通常是只读的,不再主动维护。
- Is Template:一个布尔值,指示仓库是否设置为模板。
- Default Branch:默认分支的名称。
问题确定
受欢迎的仓库分析:根据星标数量、分支数量和关注者数量,找出最受欢迎的 GitHub 仓库,了解它们的特点和受欢迎程度。
编程语言分布:查看使用不同编程语言的仓库数量,以了解哪些编程语言在 GitHub 上更受欢迎。
许可证类型分析:分析不同许可证类型的分布,以了解开源项目的许可证偏好。
问题和错误报告分析:研究仓库的问题和错误报告数量,了解项目的稳定性和开发活跃度。
项目管理功能的使用:分析是否存在项目管理功能、下载文件、Wiki 页面等,以了解仓库的功能和组织。
仓库的分类:根据主题标签对仓库进行分类,以了解 GitHub 上的不同项目领域。
通过这些更好地理解 GitHub 上的仓库,了解开源项目的趋势和特点,可帮助找到特定类型的项目来参与或使用。
受欢迎程度仓库分析
指标解析
- 星标数量(Stars):星标数量是 GitHub 上最受欢迎的度量指标之一。星标数量可以反映出用户对这个项目的兴趣程度,以及项目的影响力和流行度。排名前列的仓库通常是开源社区中最为活跃和受欢迎的项目之一。
- 分支数量(Forks):分支数量表示该项目被其他用户所复制(fork)的次数。一个高度 fork 的项目意味着这个项目既具有很高的质量,同时也具有很高的可扩展性。在开源社区中,一个高度 fork 的项目通常也代表着一个强大的开发者社区,这个社区不仅能不断改进项目本身,还能为其他开发者提供更多的学习和贡献机会。
- 关注者数量(Watchers):关注者数量是指针对一个项目的用户,最近一段时间内参与项目的人数。一个高度关注的项目通常也意味着该项目具有很强的用户参与度和开发者社区支持度。关注者数量越多,说明该项目在开源社区中的知名度、影响力和可持续性越高。
这些指标的排序可以很好地反映一个项目在开源社区中的活跃程度和质量。排名前列的项目通常也是大家学习和参与的重要来源之一,非常值得关注。
可视化分析
接下来使用python进行可视化分析,分别找出这3个指标排行前五的:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据集
github_repo = pd.read_csv('E:/data/repositories.csv', encoding='utf-8')
# 找出星标数量、分支数量和关注者数量最多的仓库
top_repos = github_repo.nlargest(5, 'Stars')
top_forks = github_repo.nlargest(5, 'Forks')
top_watchers = github_repo.nlargest(5, 'Watchers')
# 设置图表样式
sns.set(style="whitegrid")
# 创建子图
fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(10, 15), sharex=False)
# 绘制星标数量最多的仓库
sns.barplot(x='Name', y='Stars', data=top_repos, ax=axes[0])
axes[0].set_ylabel('Stargazers Count')
axes[0].set_title('Top 5 Repositories by Stargazers Count')
# 在每个柱状图上显示具体数值
for patch in axes[0].patches:
height = patch.get_height()
axes[0].annotate(f'{height}', (patch.get_x() + patch.get_width() / 2, height),
ha='center', va='bottom')
# 绘制分支数量最多的仓库
sns.barplot(x='Name', y='Forks', data=top_forks, ax=axes[1])
axes[1].set_ylabel('Forks Count')
axes[1].set_title('Top 5 Repositories by Forks Count')
# 在每个柱状图上显示具体数值
for patch in axes[1].patches:
height = patch.get_height()
axes[1].annotate(f'{height}', (patch.get_x() + patch.get_width() / 2, height),
ha='center', va='bottom')
# 绘制关注者数量最多的仓库
sns.barplot(x='Name', y='Watchers', data=top_watchers, ax=axes[2])
axes[2].set_ylabel('Watchers Count')
axes[2].set_title('Top 5 Repositories by Watchers Count')
# 在每个柱状图上显示具体数值
for patch in axes[2].patches:
height = patch.get_height()
axes[2].annotate(f'{height}', (patch.get_x() + patch.get_width() / 2, height),
ha='center', va='bottom')
# 调整子图之间的间距
plt.tight_layout()
# 展示图表
plt.show()可视化图像
可视化图像一览以便看出是否有明显区别
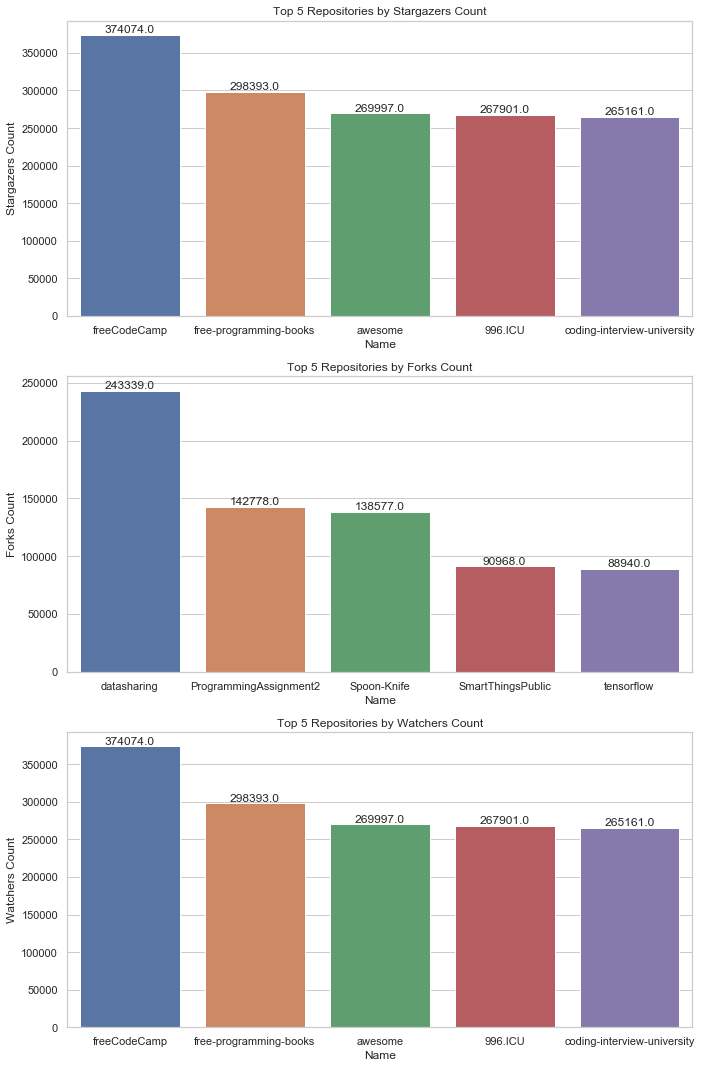
分析结果
得出结果并给出相应的仓库地址,以便读者观看
# 有了可视化的同时,顺便排序,以便后续获取dataframe表格,获取其仓库地址和homepage链接
# 按照星标数量降序排序
popular_repos_by_stars = github_repo.sort_values(by='Stars', ascending=False)
# 获取星标数量最多的仓库(Top N)
top_n_repos_by_stars = popular_repos_by_stars.head(5)
# 按照分支数量降序排序
popular_repos_by_forks = github_repo.sort_values(by='Forks', ascending=False)
# 获取分支数量最多的仓库(Top N)
top_n_repos_by_forks = popular_repos_by_forks.head(5)
# 按照关注者数量降序排序
popular_repos_by_watchers = github_repo.sort_values(by='Watchers', ascending=False)
# 获取关注者数量最多的仓库(Top N)
top_n_repos_by_watchers = popular_repos_by_watchers.head(5)星标数量:
import pandas as pd
# 假设 top_n_repos_by_stars 包含三列:Name、URL 和 Homepage
df = pd.DataFrame({
'仓库名称': top_n_repos_by_stars.Name,
'仓库链接': top_n_repos_by_stars.URL,
'主页链接': top_n_repos_by_stars.Homepage
})
### 以下为输出markdown表格,方便个人写作的
from tabulate import tabulate
# 使用每行的数据创建列表的列表
data = top_n_repos_by_stars[['Name', 'URL', 'Homepage']].values.tolist()
# 创建具有列标题的列表
headers = ['仓库名称', '仓库链接', '主页链接']
# 生成Markdown表
table_md = tabulate(data, headers=headers, tablefmt='pipe')
# 输出markdown表格
print(table_md)| 仓库名称 | 仓库链接 | 主页链接 |
|---|---|---|
| freeCodeCamp | https://github.com/freeCodeCamp/freeCodeCamp | http://contribute.freecodecamp.org/ |
| free-programming-books | https://github.com/EbookFoundation/free-programming-books | https://ebookfoundation.github.io/free-programming-books/ |
| awesome | https://github.com/sindresorhus/awesome | NAN |
| 996.ICU | https://github.com/996icu/996.ICU | https://996.icu |
| coding-interview-university | https://github.com/jwasham/coding-interview-university | NAN |
星标数量最容易反映受欢迎程度了,结合可视化图像与数据输出,此为星标排行前五的github仓库;其中,星标数最高的为freeCodeCamp,该仓库相较于其它4个有明显的差距,而其它4个趋于持平;同样是受广大github人喜爱的仓库,凭啥你最高,还高的多?访问仓库链接一探究竟:
About:freeCodeCamp.org’s open-source codebase and curriculum. Learn to code for free.—— 免费学习编程
freeCodeCamp.org是一个友好的社区,您可以在这里免费学习代码。它是由一个捐助者支持的501(c)(3)慈善机构运营的,旨在帮助数百万忙碌的成年人过渡到科技行业。我们的社区已经帮助超过4万人获得了他们的第一份开发人员工作。
原来如此,github作为广大程序员们喜爱的网站,该仓库作为免费学习编程的社区,能冲榜首合情合理, 看来我也得给这个仓库加个星标了^_^(当然,其它排行高的同样也是优秀的仓库,赶紧前往一览)
分支数量:
### 以下为输出markdown表格,方便个人写作的
from tabulate import tabulate
# 使用每行的数据创建列表的列表
data = top_n_repos_by_forks[['Name', 'URL', 'Homepage']].values.tolist()
# 创建具有列标题的列表
headers = ['仓库名称', '仓库链接', '主页链接']
# 生成Markdown表
table_md = tabulate(data, headers=headers, tablefmt='pipe')
# 输出markdown表格
print(table_md)| 仓库名称 | 仓库链接 | 主页链接 |
|---|---|---|
| datasharing | https://github.com/jtleek/datasharing | nan |
| ProgrammingAssignment2 | https://github.com/rdpeng/ProgrammingAssignment2 | nan |
| Spoon-Knife | https://github.com/octocat/Spoon-Knife | nan |
| SmartThingsPublic | https://github.com/SmartThingsCommunity/SmartThingsPublic | https://developer-preview.smartthings.com/docs/devices/hub-connected/get-started |
| tensorflow | https://github.com/tensorflow/tensorflow | https://tensorflow.org |
在开源社区中,一个高度 fork 的项目通常也代表着一个强大的开发者社区,这个社区不仅能不断改进项目本身,还能为其他开发者提供更多的学习和贡献机会;从可视化图像上看,五个柱形图,排行第一的同样明显多余其他4个,排行2,3趋于持平,4,5同样趋于持平,2,3较4,5有略高1/3的情况; 同样,分别访问,一探究竟:
通过访问datasharing,库如其名,一个数据分享指南,适用于任何需要与统计学家或数据科学家共享数据的人, 本指南的目标是提供一些关于共享数据的最佳方式的说明,以避免最常见的陷阱 以及从数据收集向数据分析过渡过程中出现延误的原因。Leek集团与一家大型 合作者的数量和结果速度变化的首要来源是数据的状态 当他们到达韭菜集团。根据我与其他统计学家的交谈,这几乎是普遍的。
如此高的fork数量,足以说明该库的内容对许多人来说是有用的,并且吸引了其他开发者来为项目做出贡献或创建自己的版本,该库的功能和内容得到了更广泛的认可和应用。
通过访问其他几个,都有fork的特点: 创建一个fork就是创建一个别人项目的个人副本。Fork充当原始存储库和您的个人副本之间的桥梁。您可以提交合并请求,通过提供对原始项目的更改来帮助改进其他人的项目。分叉是GitHub社交编码的核心。
关注者数量:
此项与星标数量是一致的,就不过多分析了,这个关注者是通过星标来关注仓库的,本质上无太大区别 ,且数据一致,这watcher可能本来是要统计github上的watch观看数量的,结果是和星标一样的了,不多赘述了哈哈哈,清楚即可;
编程语言分布
import pandas as pd
import matplotlib.pyplot as plt
# 读取GitHub仓库数据
github_repo = pd.read_csv('E:/data/repositories.csv', encoding='utf-8')
# 使用value_counts()函数计算每个编程语言的仓库数量,并选择前十名
language_counts = github_repo['Language'].value_counts().head(10).reset_index()
# 设置图表样式
plt.figure(figsize=(10, 6))
plt.bar(language_counts['index'], language_counts['Language'])
# 添加标题和标签
plt.title('Top 10 Programming Languages Distribution')
plt.xlabel('Programming Language')
plt.ylabel('Number of Repositories')
# 旋转x轴标签以避免重叠
plt.xticks(rotation=45)
# 显示图表
plt.show()
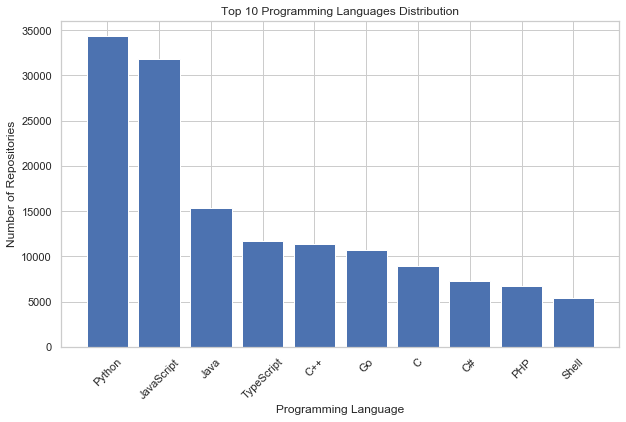
# 使用value_counts()函数计算每个编程语言的仓库数量,并选择前十名
language_counts = github_repo['Language'].value_counts().head(10)
# 输出前十名编程语言及其对应的仓库数量
print(language_counts)
# 输出
Python 34331
JavaScript 31831
Java 15298
TypeScript 11670
C++ 11391
Go 10712
C 8907
C# 7295
PHP 6741
Shell 5366
Name: Language, dtype: int64根据数据与可视化图像,可以得出以下结论:
- Python和JavaScript是排名前两位的编程语言,它们在GitHub上非常受欢迎,并且拥有数量众多的仓库。
- Java、TypeScript和C++分别排名第三、第四和第五,它们也是广泛使用的编程语言,但相对于Python和JavaScript,它们的仓库数量较少。
- Go、C、C#、PHP和Shell分别排名第六到第十,虽然它们的仓库数量较少,但仍然具有一定的流行度和应用领域。
不亏是“人生苦短,我学python”,python确实非常受欢迎,并且拥有大量的应用场景, 它大概率因易学性、灵活性和强大的数据科学功能而备受欢迎。瞧,本文便是用python做的数据分析;
许可证类型分析
import pandas as pd
import matplotlib.pyplot as plt
github_repo = pd.read_csv('E:/data/repositories.csv', encoding='utf-8')
licenses = github_repo['License']
# 计算每个许可证类型的频数,并选择前十个
top_10_license_counts = licenses.value_counts().head(10)
# 绘制饼图
plt.figure(figsize=(8, 8))
top_10_license_counts.plot(kind='pie', autopct='%1.1f%%')
plt.title('Top 10 License Types')
plt.ylabel('')
plt.show()
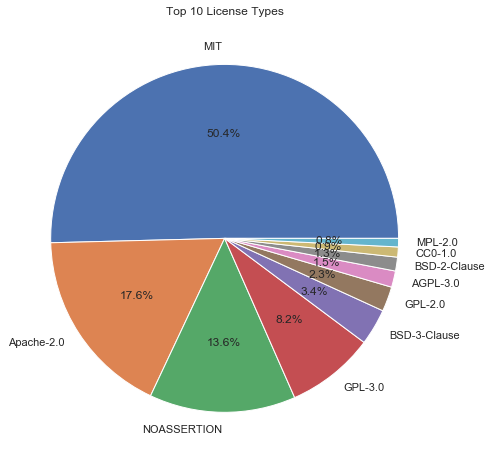
通过饼图可视化可得出以下分析结论:
- MIT许可证是最常见的许可证类型,占比高达48.40%。MIT许可证通常被认为是非常宽松的开源许可证,允许使用、修改和再发布代码,只要在相关代码中包含原始许可证声明和版权声明。
- Apache-2.0许可证位居第二,占比为16.90%。Apache-2.0许可证也是一种较为宽松的开源许可证,与MIT许可证类似,对使用、修改和再发布都有明确规定。
- NOASSERTION许可证类型占比为13.06%。”NOASSERTION”意味着无法确定具体的许可证类型,这可能是由于数据缺失或未明确指定许可证的原因。
- GPL-3.0许可证和BSD-3-Clause许可证分别占比为7.88%和3.24%。GPL-3.0是一种强 copyleft 许可证,要求在衍生作品中采用相同的许可证。而BSD-3-Clause许可证则较为灵活,允许使用、修改和再发布代码,但要求在相关代码中包含原始许可证声明和版权声明。
开源许可证的使用在软件开发中愈发普遍,而 MIT 许可证是普及度最高的一种许可证类型,MIT 许可证被广泛认可,因为它是一种简单的、宽松的许可证,可以鼓励人们分享代码并促进创新。同时,Apache-2.0许可证也备受欢迎,这表明开发人员更倾向于使用这些相对宽松的许可证类型,并且喜欢可自由使用、修改和再分发的开源许可证。
有一个比例 13.06% 的数据没有明确的许可证类型,这可能是由于数据缺失或未明确指定许可证的原因。因此,在开源社区中,开发人员应该始终注意并尊重开源组件的许可证,并遵守许可证中规定的条款和条件。
问题和错误报告分析
# 筛选Is Archived为False,Has Issues和Has Discussions字段为True的仓库
filtered_repositories = github_repo[(github_repo['Is Archived'] == False) &
(github_repo['Has Issues'] == True) &
(github_repo['Has Discussions'] == True)]
# 按Issues数量排序
filtered_repositories = filtered_repositories.sort_values(by=['Issues'], ascending=False)
# 展示结果
print(filtered_repositories[['Name', 'Issues']])import matplotlib.pyplot as plt
# 获取前十个仓库的名称和问题数量
top_10_repositories = filtered_repositories.head(10)
repository_names = top_10_repositories['Name']
issue_counts = top_10_repositories['Issues']
# 绘制柱状图
plt.figure(figsize=(10, 6)) # 调整图像大小
bars = plt.bar(repository_names, issue_counts)
plt.xlabel('Repository')
plt.ylabel('Issue Count')
plt.title('Top 10 Repositories by Issue Count')
# 旋转x轴标签,以避免重叠
plt.xticks(rotation=45)
# 压缩标签文字
for bar in bars:
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height(), bar.get_height(), ha='center', va='bottom')
plt.tight_layout() # 调整布局,以防止标签被裁剪
plt.show()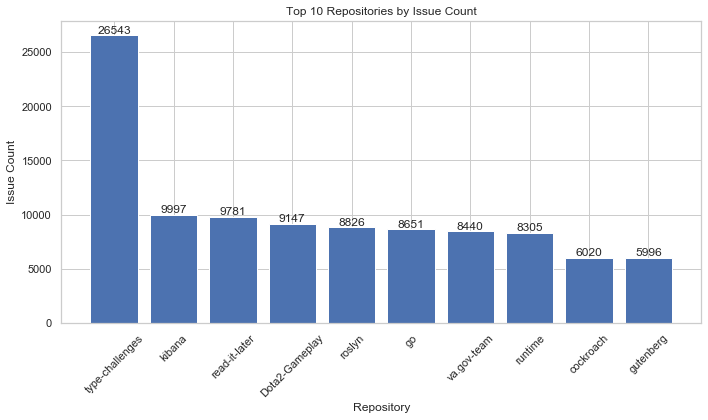
通过对三个字段:Is Archived为False 表明还未归档,Has Issues和Has Discussions字段为True,表明有issues问题和讨论,从可视化上看,此类仓库有较多的issues, 这些仓库的问题和错误报告数量较高,表明这些项目可能需要更多的开发和维护工作来解决这些问题。不过,问题报告的数量并不一定代表项目的稳定性和开发活跃度,因为一些较新的项目或活跃的社区可能会有更多的问题报告 , 只能说这些仓库有很高的讨论热度。
### 以下为输出markdown表格,方便个人写作的
from tabulate import tabulate
# 使用每行的数据创建列表的列表
data = top_10_repositories[['Name', 'URL', 'Homepage']].values.tolist()
# 创建具有列标题的列表
headers = ['仓库名称', '仓库链接', '主页链接']
# 生成Markdown表
table_md = tabulate(data, headers=headers, tablefmt='pipe')
# 输出markdown表格
print(table_md)以下是以 Markdown 表格格式输出的仓库信息:
项目管理功能使用
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
github_repo = pd.read_csv('E:/data/repositories.csv', encoding='utf-8')
# 分析Has Projects字段
projects_count = github_repo['Has Projects'].value_counts()
# 分析Has Downloads字段
downloads_count = github_repo['Has Downloads'].value_counts()
# 分析Has Wiki字段
wiki_count = github_repo['Has Wiki'].value_counts()
# 可视化分析结果
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# 绘制Has Projects字段的饼图
axes[0].pie(projects_count, labels=projects_count.index, autopct='%1.1f%%')
axes[0].set_title('Projects')
# 绘制Has Downloads字段的饼图
axes[1].pie(downloads_count, labels=downloads_count.index, autopct='%1.1f%%')
axes[1].set_title('Downloads')
# 绘制Has Wiki字段的饼图
axes[2].pie(wiki_count, labels=wiki_count.index, autopct='%1.1f%%')
axes[2].set_title('Wiki')
plt.tight_layout()
plt.show()

从可视化饼图中可以看出,三者为true的情况占比远大于false的,表明大多数仓库都具有项目管理功能、文件下载功能和Wiki页面,大多数组织非常注重项目管理和文档的维护,意味着他们在组织中重视项目的规划、跟踪和协作,并且注重文档的编写和维护。这种情况下,你可以进一步研究这些仓库,了解他们的工作流程、项目管理方法和文档编写标准,从中学习最佳实践。
仓库分类
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取CSV文件
github_repo = pd.read_csv('E:/data/repositories.csv', encoding='utf-8')
# 计算每个主题出现的次数
topics_count = {}
for topics in github_repo['Topics']:
if(isinstance(topics, str)):
for topic in topics.split(','):
if topic.strip() not in topics_count:
topics_count[topic.strip()] = 1
else:
topics_count[topic.strip()] += 1
# 输出前20个出现次数最多的主题
sorted_topics_count = sorted(topics_count.items(), key=lambda x: x[1], reverse=True)
print(sorted_topics_count[:20]) # 输出为[('[]', 101072), ("'python'", 6463), ("'javascript'", 5632), ("'hacktoberfest'", 4721), ("['android'", 4721), ("'react'", 3854), ("'machine-learning'", 3151), ("'golang'", 3058), ("'java'", 2930), ("'deep-learning'", 2790), ("'ios'", 2569), ("'nodejs'", 2442), ("'linux'", 2419), ("'php'", 2213), ("'go'", 2133), ("'pytorch'", 1976), ("'python']", 1926), ("'typescript']", 1763), ("'docker'", 1744), ("'rust'", 1617)]
# 创建词云对象
wordcloud = WordCloud(width=1200, height=800, background_color='white', colormap='tab20c', max_words=50)
# 生成词云图
word_freq = dict(sorted_topics_count)
wordcloud.generate_from_frequencies(word_freq)
# 显示词云图
plt.figure(figsize=(16, 8), dpi=200)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()

从输出的数据和可视化词云中可以得出以下一些结论:
“[]”(空标签)是最常出现的标签:词云中显示了”[]”出现了101,072次,这意味着有很多仓库没有指定具体的标签。这可能是因为标签信息缺失或者部分仓库不属于任何特定的主题领域。
编程语言占据了很大一部分:词云中显示了”python”、”javascript”、”golang”、”java”、”php”等编程语言出现的次数较多。这表明在这些仓库中,使用这些语言进行开发的项目较为常见。
技术领域和框架:词云还显示了一些技术领域和框架,如”hacktoberfest”、”android”、”react”、”machine-learning”、”deep-learning”、”pytorch”等。这些标签指示了在这些仓库中,与这些领域或框架相关的项目较为活跃。
平台和工具:词云中还显示了一些平台和工具,如”ios”、”nodejs”、”docker”、”rust”等。这些标签表示在这些仓库中,使用这些平台和工具的项目也比较常见。
结语
本文通过数据驱动的方式,从不同的维度探索了GitHub生态系统。了解了最受欢迎的项目、编程语言的分布情况,以及仓库的分类等。这些分析结果更好地了解开源开发的现状,并为开发者们提供参考和启发。通过数据的视角,能够看到开源社区的创新与共享精神,也能够发现一些有趣的趋势和发展方向。GitHub提供了一个平台,让开发者们可以相互学习、合作和分享,推动着软件开发的进步。
在未来,随着技术的不断演进和开发者的贡献,GitHub上的开源项目将继续蓬勃发展。期待着更多有趣的仓库和创新的项目的涌现,这将进一步推动开源社区的繁荣和发展。无论是作为开发者还是普通用户,都可以从GitHub的丰富资源中受益。通过参与到开源项目中,可以学习到新的技术、结识志同道合的人,并为开源社区做出贡献。
附录文件
kaggle地址:https://www.kaggle.com/datasets/donbarbos/github-repos/data
You may not use this dataset for spamming purposes, including for the purposes of selling GitHub users’ personal information, such as to recruiters, headhunters, and job boards.
数据集文件: https://bevis.lanzouq.com/ie3ym1dgzjfa
数据集文件excel版本(字段只有-‘Name’, ‘Description’, ‘URL’, ‘Homepage’,’Stars’,’Language’,’Topics’): https://bevis.lanzouq.com/iAcNa1do705g