引言
当谈到电影史上最经典的作品时,不可避免地会提及IMDb电影Top250榜单。这一榜单汇集了全球观众对电影的热爱和认可,并成为了衡量电影质量的标杆之一。作为一个电影爱好者,对这样一个充满各种类型与风格的榜单进行数据分析,让我异常兴奋。
在这篇博客中,我将探索IMDb电影Top250的数据,深入了解这些电影的特点、趋势以及对观众的影响。通过对电影的评级、票房、类型、演员、导演等因素的分析,对此做深入的了解。此次数据分析的目的不仅在于寻找那些备受赞誉的电影,更重要的是探究它们背后的故事,以及这些作品是如何引领着电影艺术的发展方向。从经典之作到当代佳片,探索这个榜单所呈现的多样性与变化。
无论您是电影爱好者、数据分析师还是仅对电影行业感兴趣的读者,本篇博客都将呈现全方位的视角与深度的分析。通过对IMDb电影Top250的数据探索,我们或许能够发现一些令人惊喜的看点和隐藏的趋势。用数据解读经典,洞察电影背后的奥秘。无论是探讨电影类型的演变,还是对导演风格的分析,揭示这些电影作品背后的魅力与价值。
数据来自kaggle公开数据集,文末附录有数据集文件与链接
数据集解析
import pandas as pd
imdb_dataset = pd.read_csv('E:/data/IMDB Top 250 Movies.csv',encoding='utf-8')
imdb_dataset.info()
# 输出 共250行数据,此为imdb的top250的电影数据
0 rank 250 non-null int64
1 name 250 non-null object
2 year 250 non-null int64
3 rating 250 non-null float64
4 genre 250 non-null object
5 certificate 250 non-null object
6 run_time 250 non-null object
7 tagline 250 non-null object
8 budget 250 non-null object
9 box_office 250 non-null object
10 casts 250 non-null object
11 directors 250 non-null object
12 writers 250 non-null object 字段解释
- rank - 电影的排名
- name - 电影名称
- year - 发布年份
- rating - 电影的评级
- genre - 电影的类型
- certificate - 电影证书
- run_time - 电影总运行时间
- tagline - 电影的标语
- budget - 电影的预算
- box_office - 全球总票房收集
- casts - 电影的所有演员阵容
- directors - 电影导演
- writers - 电影编剧
明确分析问题
电影评级分析:通过对电影评级字段进行统计和分析,了解电影评级的分布,高评级电影的类型特点、受众喜好和市场需求等,评级与票房的关系。
电影类型分析:通过对电影类型字段的处理和分析,了解当前最受欢迎的电影类型有哪些。
电影票房分析:通过对电影票房字段的分析,了解不同电影票房收益的差异、票房的分布规律、票房与其他因素(如预算、评级等)的关系等,为电影投资和营销等提供参考。
演员阵容分析:通过对演员阵容字段的处理和分析,了解电影明星的知名度、影响力、票房号召力等,为电影明星的选拔和电影制作团队的协调管理提供参考。
导演和编剧分析:通过对电影导演和编剧字段的分析,了解不同导演和编剧的风格和特点、其作品的评价和影响力、对于电影创作和团队管理等方面有指导意义。
电影年份分析:通过对电影发布年份字段的处理和分析,了解电影市场的发展趋势、不同年份电影类型、票房收益、评级等的差异和变化,为未来电影市场的预测和决策提供参考。
电影评级分析
问题细分
- 电影评级的分布:通过绘制柱状图查看电影评级的分布情况,了解高评级电影在整个数据集中的占比情况。
- 高评级电影的类型:通过绘制堆积柱状图,了解高评级电影的类型分布情况。助于了解哪些电影类型更容易获得高评级。
- 评级与票房的关系:通过绘制散点图,了解电影评级和票房之间的关系。这有助于了解高评级电影是否意味着更高的票房。
电影评级分布
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
# 设置字体为支持中文字符的字体(例如宋体、微软雅黑等)
matplotlib.rcParams['font.family'] = 'SimHei' # 使用中文字符的字体
# 读取电影数据集
imdb_dataset = pd.read_csv('E:/data/IMDB Top 250 Movies.csv', encoding='utf-8')
# 电影评级的分布
rating_counts = imdb_dataset['rating'].value_counts()
plt.bar(rating_counts.index, rating_counts.values)
plt.xlabel('电影评级')
plt.ylabel('数量')
plt.title('电影评级分布')
plt.show()
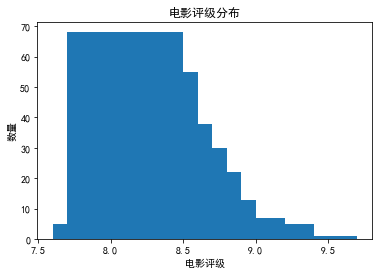
通过可视化可以得出:电影评级分数为8.0-8.5之间是最多的,8.5之后趋于不断下降,对此个人将8.5作为“高评级电影”的分界线,以助于接下来的分析:高评级电影的类型
高评级电影的类型
# 高评级电影的类型
genres = imdb_dataset['genre'].str.split(',', expand=True).stack().str.strip().value_counts()
high_rated_movies = imdb_dataset[imdb_dataset['rating'] >= 8]
genre_counts = high_rated_movies['genre'].str.split(',', expand=True).stack().str.strip().value_counts()
plt.figure(figsize=(12, 6)) # 设置图形大小为12x6英寸
plt.bar(genre_counts.index, genre_counts.values)
plt.xlabel('电影类型')
plt.xticks(rotation=45) # 将x轴标签旋转45度
plt.ylabel('数量')
plt.title('高评级电影的类型分布')
plt.tight_layout() # 使用更紧凑的布局
plt.show()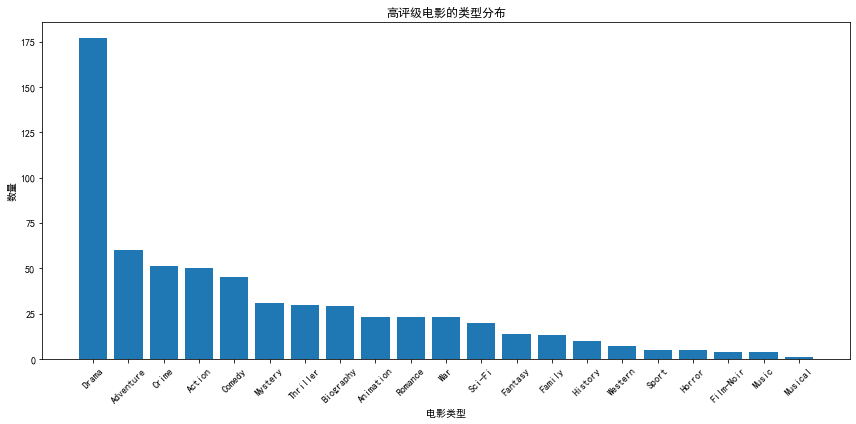
根据提供的数据,我们可以得出以下分析结论:
Drama(剧情)是高评分电影中最常见的类型,共有177部。这表明剧情片在受欢迎的高评分电影中具有较高的比例。 剧情片通常具有普遍的主题和情感,能够触动观众的内心世界,而且在制作上也比较灵活,可以涉及到各种不同的故事情节和人物形象,受众确实会比较广泛。- 其他高评分电影类型包括:
Adventure(冒险)、Crime(犯罪)、Action(动作)、Comedy(喜剧)、Mystery(悬疑)、Thriller(惊悚)、Biography(传记)、Animation(动画)等; 冒险、犯罪、动作等类型在高评分电影中占有一定比例,可能与其紧凑的节奏和刺激的情节有关。这些类型的电影往往具有高强度的视觉效果和动作场面,能够带给观众强烈的视觉冲击和情感体验 - 一些类型如
Romance(爱情)、War(战争)、Sci-Fi(科幻)、Fantasy(奇幻)等也在高评分电影中出现,尽管数量相对较少。 - 较少的高评分电影类型包括
Western(西部)、Sport(体育)、Horror(恐怖)、Film-Noir(黑色电影)等,数量相对较少。
评级与票房的关系
此分析相关字段相对特殊,需做一定的数据清洗
# 对数据进行基本的统计分析,例如计算平均值、中位数、最大值和最小值等。更好地理解数据的范围和分布情况
# 统计`rating`字段的描述性统计信息
rating_stats = imdb_dataset['rating'].describe()
print("Rating字段的描述性统计信息:")
print(rating_stats)
# 统计`box_office`字段的描述性统计信息
box_office_stats = imdb_dataset['box_office'].describe()
print("Box_office字段的描述性统计信息:")
print(box_office_stats)
# 输出
Rating字段的描述性统计信息:
count 250.000000
mean 8.307200
std 0.229081
min 8.000000
25% 8.100000
50% 8.200000
75% 8.400000
max 9.300000
Name: rating, dtype: float64
Box_office字段的描述性统计信息:
count 250
unique 221
top Not Available
freq 30
Name: box_office, dtype: object
# 看到rating字段的数据类型是float64,并且没有缺失值或异常值。对于rating字段来说,它的取值范围在8.0到9.3之间,大多数电影的评分集中在8.1到8.4之间。box_office字段的数据类型是object,并且存在缺失值(频数为30),还有221个唯一值。这意味着该字段包含了非数字的特殊值"Not Available",需要进行处理和清洗。# 获取 box_office 字段的最小值和最大值
min_box_office = imdb_dataset_copy["box_office"].min()
max_box_office = imdb_dataset_copy["box_office"].max()
print("最小票房:", min_box_office)
print("最大票房:", max_box_office)
# 输出
最小票房: 67.0
最大票房: 2799439100.0
# 做这一步的原因是:默认的刻度显示的散点图y轴过于重叠,且使用log展示不全,为确定y轴的刻度与跨度,从其票房范围来确定,最终确认,0~30亿美元,以2亿票房为跨度显示最佳可视化
import matplotlib.pyplot as plt
# 创建数据副本
imdb_dataset_copy = imdb_dataset.copy()
# 替换特殊值为缺失值
imdb_dataset_copy['box_office'] = imdb_dataset_copy['box_office'].replace('Not Available', np.nan)
# 将`box_office`字段的数据类型转换为浮点型
imdb_dataset_copy['box_office'] = pd.to_numeric(imdb_dataset_copy['box_office'], errors='coerce')
# 使用均值填充缺失值
imdb_dataset_copy['box_office'] = imdb_dataset_copy['box_office'].fillna(imdb_dataset_copy['box_office'].mean())
# 绘制散点图
plt.scatter(imdb_dataset_copy['rating'], imdb_dataset_copy['box_office'])
plt.xlabel('评级')
plt.ylabel('票房(十亿美元)')
plt.title('评级与票房的关系')
# 自定义y轴的刻度
yticks = [i*200000000 for i in range(16)]
plt.yticks(yticks)
# 显示图形
plt.show()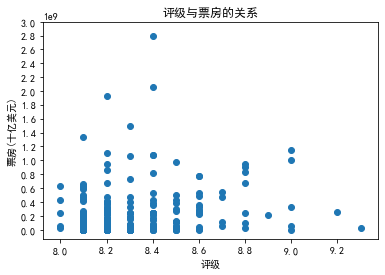
散点图如上, 点集中在8.18.6之间,且有最高点在8.4 而9.0和更高的评级反而没有高票房 ,评级为8.18.6之间能够获得较高票房,而9.0和更高的评级反而没有高票房;高评级电影并不意味着更高的票房,这确实有异于我们常人对此的看法,个人觉得可能存在以下一些原因:
评分过高导致观众期望不高。当电影评分过高时,观众往往会对电影寄予更高的期望,导致对电影的失望程度也更大。因此,即使这些电影质量较高,但是由于期望过高导致观众的不满,票房并没有达到预期。
观众偏好。在某些情况下,观众可能更喜欢具有普遍吸引力的电影,而不是过于专业或艺术化的电影。这意味着,评分过高的电影可能具有更小的观众群体,从而导致票房收入较低。
其他影响因素。除了评分以外,票房受到许多因素的影响,例如上映时间、竞争对手、导演或者演员、市场营销和宣传等等。因此,在考虑评分和票房之间的关系时,必须考虑其他因素的影响。
综上所述,评级高并不一定意味着票房一定会高。票房收入受到许多因素的影响,需要考虑这些因素与评级之间的复杂相互作用才能更好地理解票房变化的趋势,观众偏好和期望的因素也是需要考虑的重要因素。
电影类型分析
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取数据
imdb_dataset = pd.read_csv('E:/data/IMDB Top 250 Movies.csv', encoding='utf-8')
# 合并所有电影类型
all_genres = ' '.join(imdb_dataset['genre'].dropna())
# 创建词云对象
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(all_genres)
# 绘制词云图
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()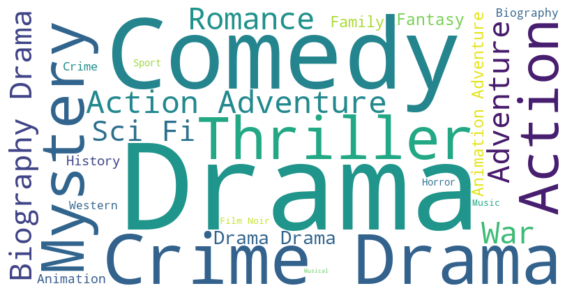
通过生成电影类型词云图,可以观察到一些关于电影类型的信息:
常见类型:可以看到一些常见的电影类型,如 Drama剧情、Comedy喜剧等。这些类型在电影市场中具有较高的普及度。
流行类型: Drama、 Crime、Comedy等显示更大和更显眼,意味着这些类型的电影可能更受欢迎。这样的类型当前最受欢迎的电影类型。
多样性:词云图中显示的电影类型的多样性可了解电影市场的种类丰富程度。存在许多不同类型的电影,说明市场上有更多选择,观众可以根据自己的喜好进行选择。
电影票房分析
票房收益的分布
import pandas as pd
imdb_dataset = pd.read_csv('E:/data/IMDB Top 250 Movies.csv',encoding='utf-8')
# 创建数据集副本
imdb_dataset_cleaned = imdb_dataset.copy()
# 获取 'box_office' 的描述性统计信息
box_office_stats = imdb_dataset_cleaned['box_office'].describe()
# 将 'box_office' 转换为数字格式
imdb_dataset_cleaned['box_office'] = pd.to_numeric(imdb_dataset_cleaned['box_office'], errors='coerce')
# 删除含有 NaN 值的行
imdb_dataset_cleaned.dropna(subset=['box_office'], inplace=True)
# 获取清理后的 'box_office' 描述性统计信息
box_office_clean_stats = imdb_dataset_cleaned['box_office'].describe()
# 输出
(count 250
unique 221
top Not Available
freq 30
Name: box_office, dtype: object,
count 2.170000e+02
mean 2.382076e+08
std 3.825392e+08
min 6.700000e+01
25% 8.574081e+06
50% 7.403672e+07
75% 3.217527e+08
max 2.799439e+09
Name: box_office, dtype: float64)import matplotlib. pyplot as plt
# 绘制直方图
plt. figure(figsize=(10, 6))
plt. hist(imdb_dataset_cleaned['box_office'], bins=50, color='skyblue', edgecolor='black')
plt. title('Distribution of Box Office Revenue')
plt. xlabel('Box Office Revenue') # 票房数量
plt. ylabel('Number of Movies') # 电影数量
plt.yscale('log')
plt.grid(True)
plt.show()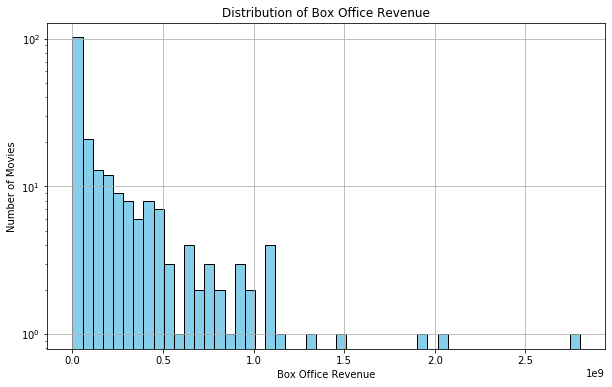
结合直方图的形状和对数尺度,可以得出以下结论:
- 大多数电影的票房收益相对较低:直方图的左侧表示票房收益较低的电影数量较多。这可能是由于市场竞争激烈、观众选择性增加以及市场需求等因素导致的。
- 少数电影的票房收益非常高:直方图的右侧表示票房收益较高的电影数量较少,但它们的收益非常显著。这些电影可能是大片、IP改编、明星阵容强大或口碑极佳的作品,能够吸引更多观众并带来巨大的票房收入。
通过分析这种左偏分布,电影产业中的从业者可以更好地了解市场行情,制定适当的营销策略和商业决策。同时,观众也可根据这一分布特征更好地预期电影的票房表现。
票房与预算的关系
# 首先检查 'budget' 和 'box_office' 列的数据类型
imdb_dataset[['budget', 'box_office']].dtypes
# 创建数据框的副本
cleaned_imdb_dataset = imdb_dataset.copy()
# 将 'budget' 和 'box_office' 列转换为数值型数据,将错误强制转换为 NaN
cleaned_imdb_dataset['budget'] = pd.to_numeric(cleaned_imdb_dataset['budget'], errors='coerce')
cleaned_imdb_dataset['box_office'] = pd.to_numeric(cleaned_imdb_dataset['box_office'], errors='coerce')
# 删除 'budget' 和 'box_office' 列中包含 NaN 值的行
cleaned_imdb_dataset = cleaned_imdb_dataset.dropna(subset=['budget', 'box_office'])
# 确认更改
cleaned_imdb_dataset[['budget', 'box_office']].dtypes, cleaned_imdb_dataset.shape
import matplotlib.pyplot as plt
# 绘制散点图
plt.figure(figsize=(10,6))
plt.scatter(cleaned_imdb_dataset['budget'], cleaned_imdb_dataset['box_office'], alpha=0.5)
plt.title('预算与票房的关系')
plt.xlabel('预算(美元)')
plt.ylabel('票房(美元)')
plt.grid(True)
plt.show()
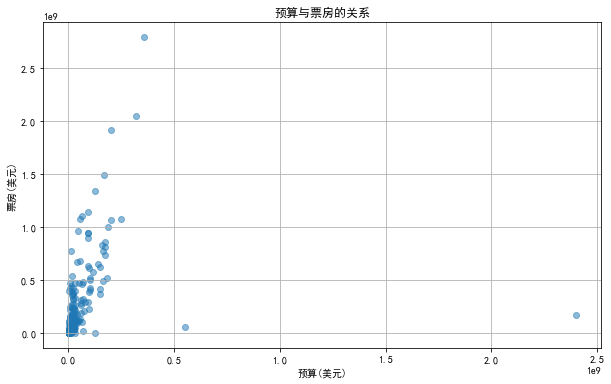
预算和票房收益之间的散点图在前部分趋向于线性关系时,可以得出以下总结:
- 正相关性:预算和票房收益呈现出正相关性,即随着预算的增加,票房收益也有增加的趋势。这意味着更高的预算可能会产生更高的票房收益。
- 异常值:散点图中可能存在一些异常值,即在整体趋势之外的点。这些异常值可能是由于特定电影的独特情况导致的,例如超高或超低的预算但仍获得了显着的票房收益。
- 线性度:尽管存在一些异常值,但总体趋势显示出预算和票房收益之间的线性关系。这意味着在一定程度上,预算的增加往往伴随着票房收益的增加,尽管并非完全线性。
- 数据范围:散点图展示了预算和票房收益的实际数值范围。通过观察散点图,可以看到预算和票房收益都涵盖了广泛的数值范围,从较低的值到非常高的值。
散点图展示了预算和票房收益之间的趋势和关系。散点图只是展示了数据之间的关联性,不能用于确定因果关系。其他因素如市场营销、电影类型等也可能对票房收益产生影响。
演员阵容分析
了解电影明星的知名度和票房号召力,确定出现次数最多的演员以及他们的电影平均票房。
from collections import defaultdict
# 分割演员表并创建一个字典来统计演员出现次数和票房总和
actor_frequency = defaultdict(int)
actor_box_office = defaultdict(float)
for index, row in imdb_dataset_cleaned.iterrows():
actors = row['casts'].split(',')
for actor in actors:
actor = actor.strip()
actor_frequency[actor] += 1
try:
box_office = float(row['box_office'])
actor_box_office[actor] += box_office
except ValueError:
pass
# 计算每个演员的平均票房
actor_average_box_office = {actor: box_office / actor_frequency[actor] for actor, box_office in actor_box_office.items()}
# 转换为DataFrame以便更容易分析
actor_frequency_df = pd.DataFrame(list(actor_frequency.items()), columns=['Actor', 'Movies_Count'])
actor_box_office_df = pd.DataFrame(list(actor_average_box_office.items()), columns=['Actor', 'Average_Box_Office'])
# 在'Actor'上合并两个数据框
actors_analysis_df = actor_frequency_df.merge(actor_box_office_df, on='Actor')
# 获取电影数量最多和平均票房最高的前10位演员
top_actors_by_count = actors_analysis_df.sort_values(by='Movies_Count', ascending=False).head(10)
top_actors_by_box_office = actors_analysis_df.sort_values(by='Average_Box_Office', ascending=False).head(10)
top_actors_by_count, top_actors_by_box_office
# 输出
( Actor Movies_Count Average_Box_Office
53 Robert De Niro 9 1.755030e+08
862 John Ratzenberger 7 6.829208e+08
222 Harrison Ford 7 3.999400e+08
1 Morgan Freeman 7 4.561752e+08
39 Michael Caine 6 6.969114e+08
36 Christian Bale 6 5.056329e+08
205 Leonardo DiCaprio 5 4.512174e+08
23 Robert Duvall 5 8.549490e+07
709 Charles Chaplin 5 3.111176e+05
162 Tom Hanks 5 5.818260e+08,
Actor Movies_Count Average_Box_Office
1160 Tessa Thompson 1 2.799439e+09
1156 Jeremy Renner 1 2.799439e+09
1161 Rene Russo 1 2.799439e+09
1157 Paul Rudd 1 2.799439e+09
1159 Evangeline Lilly 1 2.799439e+09
962 Karen Gillan 2 2.425927e+09
960 Chadwick Boseman 2 2.425927e+09
956 Chris Evans 2 2.425927e+09
953 Robert Downey Jr. 2 2.425927e+09
965 Elizabeth Olsen 2 2.425927e+09)根据这个输出结果,可以看到出场次数排名前十的演员以及他们的出演次数和平均票房收益。其中我个人比较眼熟的有:Charles Chaplin(卓别林)、 Morgan Freeman ( 摩根弗里曼 )、 Leonardo DiCaprio ( 莱昂纳多·迪卡普里奥 )。其中卓别林的平均票房是最低的,这是一个特殊的地方,跟卓别林所处的时代背景有关。
这些数据可以用来评估演员在电影行业的影响力和票房号召力。从数据中可以看出,一些演员的平均票房收益相对较高,可能意味着他们的电影更受欢迎并能够吸引更多观众。比如Michael Caine,虽然只出演6部,但是平均票房是十个中最高的;当然,这个数据集可能只是针对特定的时间段或特定类型的电影,因此不能完全代表演员整个职业生涯的票房成绩
在这个演员电影数平均票房数前十中,个人仔细观察了一下,居然有8位是扮演漫威宇宙里角色的演员,如钢铁侠扮演者-Robert Downey Jr. ,美国队长扮演者-Chris Evans,绯红女巫扮演者-Elizabeth Olsen等等,漫威电影的票房确实在很多时候高居榜首,我个人也是个漫威粉,没少去电影院看哈哈哈。
对于平均票房排行前十的可以看出, 这些演员的平均票房收益都非常高,约为27.99亿美元,这是由于这些电影的影响力很大,受到了全球观众的广泛关注。这些演员在演技方面也有不俗的表现,他们通过精湛的表演为电影的成功做出了贡献。
导演和编剧分析
# 定义一个函数来计算导演和编剧的出现次数
def count_occurrences(column):
# 将条目按逗号分隔并堆叠到单列中
occurrences = column.str.split(',').apply(pd.Series, 1).stack()
# 去除姓名周围的空格
occurrences = occurrences.str.strip()
# 统计每个姓名的出现次数
occurrence_count = occurrences.value_counts()
return occurrence_count
# 计算导演和编剧的出现次数
directors_count = count_occurrences(imdb_dataset['directors'])
writers_count = count_occurrences(imdb_dataset['writers'])
# 显示基于出现次数的前10名导演和编剧
top_directors = directors_count.head(10)
top_writers = writers_count.head(10)
top_directors, top_writers
# 输出
(Stanley Kubrick 7
Martin Scorsese 7
Akira Kurosawa 7
Steven Spielberg 7
Christopher Nolan 7
Alfred Hitchcock 6
Charles Chaplin 5
Quentin Tarantino 5
Billy Wilder 5
Sergio Leone 4
dtype: int64,
Christopher Nolan 7
Stanley Kubrick 7
Akira Kurosawa 6
George Lucas 5
Quentin Tarantino 5
Billy Wilder 5
Pete Docter 5
Jonathan Nolan 5
Charles Chaplin 5
Andrew Stanton 4
dtype: int64)
这些导演和编剧的作品数量多,表明他们在电影领域具有很高的影响力和评价。
在这榜单的前十名中,可以发现几位备受瞩目的导演,他们的名字无疑是耳熟能详的电影界巨匠。这包括 Steven Spielberg(史蒂文·斯皮尔伯格)、Christopher Nolan(克里斯托弗·诺兰)、Charles Chaplin(查尔斯·卓别林)。
史蒂文·斯皮尔伯格是一位全球知名的导演,以他出色的技艺和故事讲述能力而著称。他的作品涵盖了多个题材,包括惊悚片《大白鲨》、科幻经典《E.T.外星人》以及历史剧《辛德勒的名单》等,每一部影片都展现了他对细节的精准掌控和情感深度的表达。他的三部电影《大白鲨》(1975年)、《E.T.外星人》(1982年)和《侏罗纪公园》(1993年)更是打破了票房记录,成为当时最卖座的电影之一。个人也很喜欢看他的电影,他的《拯救大兵瑞恩》的电影让我真切感受到了真实的战争场景,深刻感受到战争的残酷和牺牲,也是一部经典的作品。
克里斯托弗·诺兰是当代影坛最具创意和影响力的导演之一。他以独特的叙事手法和视觉效果引领着电影技术的发展,并以其扣人心弦的作品赢得了广泛的赞誉。从复杂的心理悬疑片《盗梦空间》到超级英雄大片《蝙蝠侠:黑暗骑士》系列,诺兰的作品总是充满着深度和纷繁复杂的层次。他的《星际穿越》展现的视觉效果也让我叹为观止,这绝对是一部充满创意和深度的电影,通过视觉效果和演员表现,在科幻电影领域树立了标杆。如果你喜欢探索未知、寻找答案,那么这部电影绝对值得一看。
查尔斯·卓别林则是电影史上的传奇人物,他以其标志性的小丑形象和喜剧才华而闻名。他的作品不仅带给观众欢乐,更融入了对社会现实的思考与关怀。无论是《大独裁者》中表达的对法西斯主义的讽刺,还是《摩登时代》中对工业化时代的反思,卓别林总是通过他的影片引发人们对人性与社会问题的思考。
这三位导演的存在使IMDb电影Top250榜单更加多样化和精彩。他们各自独特的风格和作品不仅赢得了观众的喜爱,也推动着电影艺术的进步与发展。无论是斯皮尔伯格的情感深度、诺兰的技术创新还是卓别林的社会关怀,这些导演的作品永远会在电影史上占据重要的位置,为我们带来无尽的欣赏与思考。
def average_rating(column, dataset):
# 通过逗号分隔并映射到它们各自的评分
expanded = column.str.split(',').apply(lambda x: pd.Series(x).str.strip()).stack()
index = expanded.index.get_level_values(0)
expanded_df = dataset.loc[index].copy()
expanded_df['person'] = expanded.values
# 按照人员进行分组,并计算平均评分
average_ratings = expanded_df.groupby('person')['rating'].mean().sort_values(ascending=False)
return average_ratings
# 计算导演和编剧的平均评分
directors_avg_rating = average_rating(imdb_dataset['directors'], imdb_dataset)
writers_avg_rating = average_rating(imdb_dataset['writers'], imdb_dataset)
# 显示前10名基于平均评分的导演和编剧
top_directors_avg_rating = directors_avg_rating.head(10)
top_writers_avg_rating = writers_avg_rating.head(10)
top_directors_avg_rating, top_writers_avg_rating
# 输出
(person
Frank Darabont 8.950000
Francis Ford Coppola 8.900000
Peter Jackson 8.866667
T.J. Gnanavel 8.800000
Irvin Kershner 8.700000
Lilly Wachowski 8.700000
Lana Wachowski 8.700000
Robert Zemeckis 8.650000
Fernando Meirelles 8.600000
Jonathan Demme 8.600000
Name: rating, dtype: float64,
person
Mario Puzo 9.100000
Reginald Rose 9.000000
Steven Zaillian 9.000000
Thomas Keneally 9.000000
Frank Darabont 8.950000
Francis Ford Coppola 8.900000
Philippa Boyens 8.866667
Fran Walsh 8.866667
J.R.R. Tolkien 8.866667
T.J. Gnanavel 8.800000
Name: rating, dtype: float64)在导演平均评分前十中,有著名的Frank Darabont(弗兰克·达拉邦特),他的编剧作品在平均评分上位列第一,可能因为他编写了备受赞誉的电影《肖申克的救赎》(The Shawshank Redemption),该电影在观众和评论家中都备受喜爱。
Francis Ford Coppola(弗朗西斯·福特·科波拉,他编写了经典的电影《教父》(The Godfather)系列,该系列也备受好评。
Peter Jackson(彼得·杰克逊):他编写了电影《指环王》(The Lord of the Rings)系列,该系列在世界范围内获得了巨大的成功和认可。
在编剧评分前十中,Mario Puzo(马里奥·普佐):他是《教父》系列小说的作者,这些小说后来被改编成备受喜爱的电影。
Thomas Keneally(托马斯·凯尼利):他可能是与电影《辛德勒的名单》(Schindler’s List)有关的小说作者,该电影由史蒂文·斯皮尔伯格执导。
Philippa Boyens(菲莉帕·博恩斯):她是《指环王》系列电影的编剧之一,该系列在电影史上取得了重大成功。
Fran Walsh(弗兰·沃尔什):她也是《指环王》系列电影的编剧之一,与Philippa Boyens一起合作。
J.R.R. Tolkien(J.R.R.托尔金):尽管他是小说的作者而不是编剧,但他的小说《指环王》是《指环王》电影系列的基础,对电影的成功产生了重要影响。
指环王的相关编剧的评分都挺高的,这也为指环王系列电影的成功垫底了基础。他们对原著的忠实呈现和深入理解,以及对于细节和真实感的重视,使得该系列电影成为了奇幻电影史上的经典之作。
总的来说,这些编剧都在电影界留下了自己的印记,他们的作品与备受赞誉的电影和文学作品相关联,许多人因其卓越的创作而备受认可。
电影年份分析
为了进行电影年份分析,将专注于year字段,以及与类型、票房收入和评级相关的字段。
# 将 'year' 列转换为日期时间格式,并提取年份(如果年份不是标准的年份格式)
imdb_dataset['year'] = pd.to_datetime(imdb_dataset['year'], format='%Y', errors='coerce').dt.year
# 检查年份列是否有空值,以确保转换成功
year_nulls = imdb_dataset['year'].isnull().sum()
# 统计每年的电影数量
movies_per_year = imdb_dataset['year'].value_counts().sort_index()
# 对 'year' 列进行基本统计分析
year_stats = imdb_dataset['year'].describe()
year_nulls, movies_per_year, year_stats
# 输出
(0,
1921 1
1924 1
1925 1
1926 1
1927 1
..
2018 4
2019 6
2020 2
2021 2
2022 1
Name: year, Length: 86, dtype: int64,
count 250.000000
mean 1986.360000
std 25.125356
min 1921.000000
25% 1966.250000
50% 1994.000000
75% 2006.000000
max 2022.000000
Name: year, dtype: float64)从输出可得出电影年份的一些统计数据:
- 最早的电影是从1921年的。
- 数据集中的电影主要集中在1986年左右,这是平均值。
- 中位数年份是1994,这意味着一半的电影在这一年或之前发行,另一半在这一年之后发行。
- 最新的电影是从2022年的。
使用这些数据来分析电影的发展趋势,特别是电影的数量、类型、票房收入和评级随时间的变化。
通过绘制电影数量随年份变化图,探索不同年代的流行电影类型,以及票房收入和评级的趋势。
import matplotlib.pyplot as plt
# 会自动电影数量年份变化图
plt.figure(figsize=(14,7))
movies_per_year.plot(kind='line')
plt.title('多年来IMDB排名前250的电影数量')
plt.xlabel('年份')
plt.ylabel('电影数量')
plt.grid(True)
plt.show()
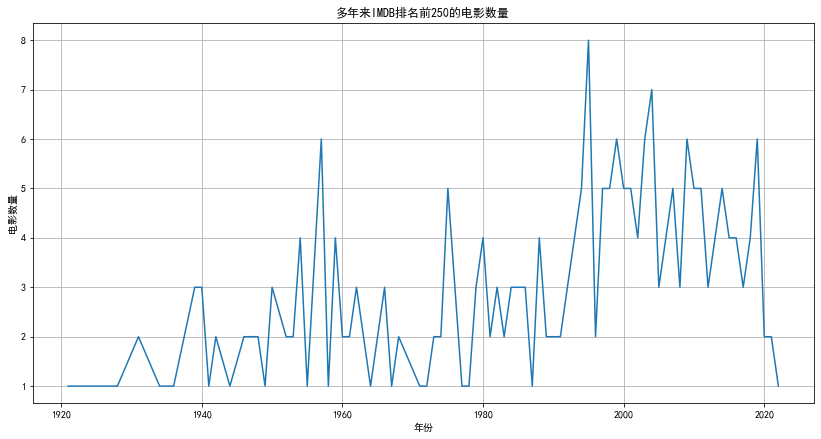
从图表中可以看出,IMDB前250名的电影数量随着时间的推移而变化,尤其是从20世纪60年代末期开始逐渐增加,直到21世纪初达到峰值。近年来的电影数量有所减少,这可能是因为较新的电影还没有足够的时间积累与旧电影相同的声望或评分。
分析不同年份的电影类型的分布情况。由于genre字段可能包含多个类型,先将这些类型分开,然后计算每种类型的电影数量。同时探索票房收入和评级如何随时间变化。
首先处理genre字段,查看不同年份最受欢迎的电影类型。
# 将 genre 列拆分,并计算每个流派每年的电影数量
genres_by_year = imdb_dataset.drop('genre', axis=1).join(imdb_dataset['genre'].str.split(',', expand=True).stack().reset_index(level=1, drop=True).rename('genre'))
genres_by_year['genre'] = genres_by_year['genre'].str.strip() # 清理任何前导/尾随空格
genre_counts = genres_by_year.groupby(['year', 'genre']).size().unstack(fill_value=0)
# 绘制不同类型电影在不同年份的分布情况
plt.figure(figsize=(15,8))
genre_counts.plot(kind='area', stacked=True, figsize=(15,8))
plt.title('不同流派电影的年度分布')
plt.xlabel('年份')
plt.ylabel('电影数量')
plt.legend(title='流派', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True)
plt.show()
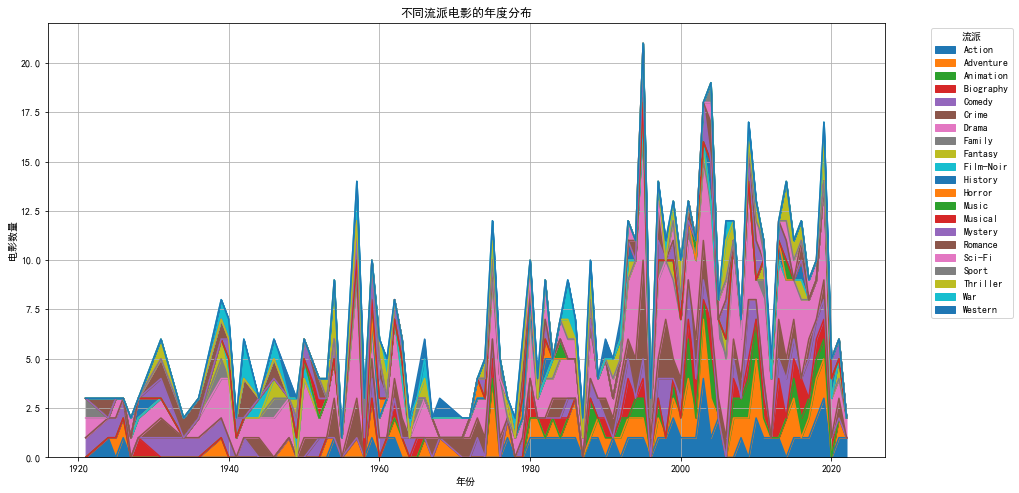
电影类型随时间的分布显示了哪些类型随时间变得更受欢迎。例如,我们可以看到某些类型(如剧情片和犯罪片)在整个时间段内都非常流行,而其他类型则可能在特定时期内流行。
结语
这次关于IMDb电影Top250的数据分析中,探索了电影历史中的一些最杰出的作品,深入了解了它们的特点、趋势以及对观众的深刻影响。这一榜单代表了电影艺术的巅峰,反映了观众对多样性和创新的热切追求。
通过对这些电影的评分、类型、导演和其他关键因素的分析,不仅找到了众多备受赞誉的电影,还深入挖掘了它们背后的故事和影响。这些作品的背后是导演、编剧、演员和整个电影制作团队的努力和才华,它们在电影历史上留下了不可磨灭的印记。
无论您是电影爱好者、数据分析师还是仅对电影行业感兴趣的读者,本次数据探索都为您呈现了丰富的视角和深刻的分析。希望这次深入研究电影数据的旅程让您更深入地了解了这些经典之作,以及它们如何引领着电影艺术的发展方向。
附录
imdb_top250数据集: https://bevis.lanzouq.com/isMBr1dkyera
kaggle地址:https://www.kaggle.com/datasets/rajugc/imdb-top-250-movies-dataset